Nowcasting employment in the euro area
Marta Bańbura, Irina Belousova, Nowcasting employment in the euro

Katalin Bodnár, Máté Barnabás Tóth area
Disclaimer: This paper should not be reported as representing the views of the European Central Bank (ECB). The views expressed are those of the authors and do not necessarily reflect those of the ECB.
Abstract
Euro area labour market variables are published with a considerable lag, longer than in the case of real GDP. We develop a suite of models to provide a more timely estimate (nowcast) of euro area quarterly employment growth based on a broad range of monthly indicators. The suite includes a batch of different dynamic factor model and bridge equation specifications. We evaluate it in real time over 2013-2022 and find that (i) monthly indicators provide useful information for a timely assessment of employment developments with unemployment rates and sentiment indicators containing most of the relevant information, (ii) the performance of small-scale models is comparable to those based on a larger information set, (iii) the suite performs favourably compared to the Eurosystem/ECB staff macroeconomic projections, (iv) forecasting performance deteriorates temporarily at the initial stage of the COVID-19 pandemic period, but the models outperform the benchmarks again thereafter.
JEL Classification: C53, E24, E32, E37
Keywords: Forecasting, Real-Time Data, Mixed Frequency
Non-technical summary
This paper presents a suite of models to predict (nowcast”) euro area employment growth for the current and the next quarter. The modelling framework exploits timely information from monthly and quarterly data that are characterised by non-synchronous publication dates (ragged” edge).
Timely information on labour market variables is important from a monetary policy perspective. In particular, they help to assess the medium-term inflationary pressures arising from labour markets. In contrast to the US, euro area key labour market indicators, such as employment or hours worked, are published at quarterly frequency and with a considerable delay.
Nowcasting has been an area of active academic research for several years and many policy institutions have implemented models to assess economic activity in real time, exploiting a highfrequency data flow. The target variable of such approaches is typically quarterly GDP growth. By contrast, labour market variables, and in particular employment growth, have received much less attention. We propose to use more timely and higher (monthly) frequency data, such as unemployment statistics, sentiment indicators or negotiated wages for gauging the state of the labour market and for generating nowcasts of quarterly employment growth.
The suite of models proposed in this paper consists of several specifications of bridge equations and dynamic factor models (DFMs). A bridge equation links the low frequency (quarterly) target variable to one or more observable higher frequency (monthly) indicators. The latter are aggregated to the lower frequency in order to estimate the equation and compute the forecast for the target variable. Bridge equations are widely used in policy institutions for nowcasting, due to their simple setup. Dynamic factor models assume that each observed variable in the information set can be decomposed into a common component driven by a few common factors and a remainder (the idiosyncratic component). Thus the DFMs can exploit the information content of a large dataset, including both monthly and quarterly variables, by extracting a small number of latent factors that drive the bulk of the co-movement across the series.
In this paper, to produce nowcasts that are robust to model uncertainty, we use different specifications of the two model classes described above and average the resulting predictions. In case of bridge equations, the specifications differ in terms of (i) the number and the type of monthly variables included in the equations, (ii) the auxiliary models used to forecast the monthly predictor variables or (iii) the quarterly variables included as explanatory variables in the equation. The DFMs include specifications at mixed frequency (monthly and quarterly) and at monthly frequency (with all quarterly data interpolated). The mixed frequency category contains versions where the latent factors are only related to a selected group of variables (block” specific factors) and specifications with and without GDP growth. For all these versions, we consider several parameterisations in terms of number of factors and of the lags in the time series processes assumed to govern their evolution.
We use a wide range of ’hard’ and ’soft’ indicators for the euro area, both at monthly and quarterly frequency. These include (i) quarterly indicators on the labour markets and economic activity from the national accounts (e.g. total employment, total hours worked, GDP, compensation of employees), (ii) monthly hard indicators related to activity and labour markets (e.g. unemployment rates for different demographic groups, industrial production), (iii) monthly soft indicators related to activity and labour markets (Purchasing Managers’ surveys and European Commission consumer and business confidence surveys), (iv) monthly indicators on nominal developments (e.g. inflation and internal calculations on negotiated wages at monthly frequency).
The forecasting performance of the models is evaluated using real-time data vintages over 2013-2022, including the highly volatile period of the COVID-19 pandemic, which is analysed separately from the preceding sample. The real-time database contains the snapshots of the available data at given points in time and thus reflects its ’ragged edge’ structure due to historic publication patterns and also tracks data revisions.
The main results are as follows. First, monthly indicators provide useful information for a timely assessment of employment developments in the euro area as the model suite clearly outperforms a na¨ive benchmark. Second, with the exception of the initial stage of the pandemic, the performance of small scale (bridge equation) models is comparable to those based on a larger information set (DFMs). Thus, unemployment rates and sentiment indicators appear to contain most of the relevant information. Third, the suite performs favourably compared to the Eurosystem/ECB staff macroeconomic projections. Specifically, it has a comparable average accuracy as the projections with respect to the first official estimates of employment, and a higher accuracy with respect to the latest release of employment growth. In both cases the model suite features a smaller bias. This is a notable result since judgemental forecasts are typically hard to beat by purely model-based forecasts. Fourth, focusing on the COVID-19 pandemic period, the (relative) forecasting performance deteriorates temporarily in 2020, but the models outperform the benchmarks again thereafter.
1 Introduction
This paper presents a suite of models that can be regularly used for nowcasting employment in the euro area.
Labour market variables are important from a monetary policy perspective as they can contain useful extra information, compared to real GDP, on the medium term inflationary pressures arising from labour markets, e.g. via wage growth. However, at the euro area level, key indicators, such as employment, hours worked or compensation, are only available at quarterly frequency and with a considerable delay. In particular, Eurostat publishes the first (flash) aggregate euro area estimate of quarterly total employment 45 days after the end of the reference quarter, compared to 30 days for the preliminary flash estimate of GDP.[1]The second and more complete aggregate estimate of total employment, which is published together with the first release for other labour market variables (for example, total hours worked, sectoral employment and compensation per employee), is released about 66 days after the end of the reference quarter. In the meantime, more timely and higher frequency data, such as monthly unemployment statistics, sentiment indicators, negotiated wages or consumer prices can contain useful information about the state of the labour market and thus can be used to derive nowcasts of the key quarterly variables well before they are officially published.
Starting with the seminal papers of Evans (2005) and Giannone et al. (2008), over the past 15 years nowcasting has been an active area of academic research (see e.g. Ban´bura et al., 2013, Hirschbu¨hl et al., 2021, for a literature review). Also, many policy institutions have implemented nowcasting models in order to assess economic developments in real time. The target variable of such approaches is typically quarterly GDP growth.[2]By contrast, labour market variables, and in particular employment growth, have received much less attention. While central banks routinely monitor high frequency data to assess the state of the labour markets, these data are seldom used systematically to deliver early estimates of lower frequency (quarterly) labour market variables. One reason for this could be that many studies and applications focus on the US where, in contrast to the euro area, the data on e.g. employment, hours worked and hourly earnings is available at monthly frequency and with shorter publication delays.[3]
The suite of models proposed in this paper consists of several specifications of bridge equations and dynamic factor models, which are standard building blocks in the nowcasting literature. The models are similar to those used for nowcasting euro area GDP growth at the ECB (Ban´bura and Saiz, 2020) and US GDP growth at the Federal Reserve Bank of New York (Bok et al., 2018). The framework allows to exploit information from a large number of indicators at monthly and quarterly frequency released asynchronously, that is with different publication lags (ragged edge).[4]The indicators cover a broad range of categories, including quarterly labour market data and GDP growth, monthly hard indicators on real activity and unemployment rates, monthly sentiment indicators and monthly nominal indicators such as negotiated wages (internal calculations at the monthly frequency) and inflation.
The models are evaluated in real-time setting over 2013-2022, including the COVID-19 pandemic period. We compare their performance to a na¨ive, random walk, benchmark and to the quarterly Eurosystem/ECB staff macroeconomic projections.[5]The latter are derived as aggregations of country-level projections and include a large amount of information processed via models and expert judgement. For this reason, they can be considered as a benchmark not easy to beat.
The main results are as follows. First, monthly indicators provide useful information for a timely assessment of employment developments in the euro area as the model suite clearly outperforms the random walk benchmark. Second, with the exception of the initial stage of the pandemic, the performance of small scale (bridge equation) models is comparable to those based on a larger information set (dynamic factor models). Thus, unemployment rates and sentiment indicators appear to contain most of the relevant information while the DFM class seems to provide some hedge against extreme volatility. Third, the suite performs favourably compared to the Eurosystem/ECB staff macroeconomic projections. Specifically, it has a comparable average accuracy as the projections with respect to the first official estimates of employment, and a higher accuracy with respect to the latest employment growth data. In both cases the model suite features a smaller bias (mean error). This is a notable result since judgemental forecasts are typically hard to beat by purely model-based forecasts.[6]Fourth, focusing on the COVID-19 pandemic period, the (relative) forecasting performance deteriorates temporarily in 2020, but the models outperform the benchmarks again thereafter. In other words, when abstracting from the weak forecast performance at the initial stage of the pandemic, there seems - for now - no need to adjust the models in order to deal with pandemic observations”.
Regarding the related literature - whereas there is a large and growing number of studies that aim at nowcasting GDP and/or its components - work on labour market variables is much scarcer in the forecasting literature. Closest to our approach is that of Karagedikli and Ozbilgin¨ (2019) who use MIDAS models to nowcast several labour market variables for New Zealand and of Rapach and Strauss (2008) who use different models and forecast combinations to forecast monthly US employment growth. More recently, Consolo et al. (2023) focus on the euro area labour market and use a Bayesian Mixed-Frequency VAR model, with the double aim of forecasting labour market variables and providing an economic interpretation about their drivers. Among the labour market variables, the monthly unemployment rate is often the focus of shortterm forecasting approaches. In particular, several recent papers have investigated the usefulness of the high frequency information from Google trends (see e.g. Askitas and Zimmermann, 2009, Fondeur and Karam´e, 2009, Naccarato et al., 2018, Koop and Onorante, 2019, Borup et al., 2022, Aaronson et al., 2022), or LinkedIn hiring data (Botelho and Consolo, 2021). The former source of information has been recently also used to forecast (monthly) employment growth in the United States (Borup and Schu¨tte, 2020). Focusing on the pandemic period, Larson and Sinclair (2022) found that using the timing of emergency declarations across the states to nowcast US initial unemployment claims outperformed the models using Google trends.
The rest of the paper is organised as follows. Section 2 describes the modelling approaches we adopt for the nowcasting of euro area employment growth. Section 3 provides details on data set construction and sources. Section 4 contains the real-time forecast evaluation exercise, where Section 4.1 focuses in particular on the period of the pandemic. Section 5 concludes. Appendices contain detailed descriptions of the dataset and the models as well as additional
results.
2 Modelling framework
2.1 Bridge equations
A bridge equation links a low frequency target variable to one or more (observed) higher frequency indicator(s). The latter are aggregated to lower frequency in order to estimate the equation and compute the forecast for the target variable. Own lags and other low frequency variables might be included as well as explanatory variables.
In the present application we allow one or two monthly predictors. As for quarterly variables we either include the lagged dependent variable (given the high persistence of employment growth) or lagged GDP growth (as employment growth for the total economy tends to lag aggregate output growth).[7]Specifically, we estimate the following bridge equations:
![]() , (1)
, (1)
where![]() denotes quarter-on-quarter growth of employment, XjtQ is a monthly indicator aggregated to quarterly frequency (also in quarter-on-quarter terms) and k = 1 or k = 2. In versions including lagged GDP growth we replace
denotes quarter-on-quarter growth of employment, XjtQ is a monthly indicator aggregated to quarterly frequency (also in quarter-on-quarter terms) and k = 1 or k = 2. In versions including lagged GDP growth we replace![]() in the right-hand side by the former variable.
in the right-hand side by the former variable.
Monthly predictors are selected on the basis of contemporaneous correlations and the forecasting performance. The following five variables were found to be the most useful: headline unemployment rate (aged 15-74), youth unemployment rate (aged 15-24), unemployment rate of the 25-74 population, economic sentiment indicator (ESI), and the PMI composite employment indicator. In the specifications with one monthly predictor, we use the youth unemployment rate (aged 15-24), the unemployment rate of the 25-74 population, or one of the sentiment indicators. In the specifications with two monthly predictors, we use the overall unemployment rate combined with either the ESI or the PMI indicator.
The link between the target variable and the monthly predictors in equation (1) is contemporaneous. Consequently, the latter variables typically need to be forecast for (some of) the months of the target quarter. This is done using auxiliary models, in particular Bayesian VARs, Bayesian AR models and simple ARMA models. In case of the latter, the optimal number of lags (p) and the number of moving average terms (q) are chosen using Bayesian (Schwarz) inTable 1: Overview of the bridge equation specifications
Explanatory variables Forecasting of expl. variables | ||
Bridge equations with one monthly variable | ||
1 | Unemployment rate (over 25) | Bayesian AR(6) |
2 | Unemployment rate (under 25) | Bayesian AR(6) |
3 | Markit. Composite - Employment (total) | Bayesian AR(6) |
4 | Bayesian AR(6) | |
5 | Unemployment rate (over 25) | Bayesian VAR(6) with 4 variables |
6 | Unemployment rate (under 25) | Bayesian VAR(6) with 4 variables |
7 | Markit. Composite - Employment (total) | Bayesian VAR(6) with 4 variables |
8 | Bayesian VAR(6) with 4 variables | |
9 | Unemployment rate (over 25) | ARMA |
10 | Unemployment rate (under 25) | ARMA |
11 | Markit. Composite - Employment (total) | ARMA |
12 | ARMA | |
Bridge equations with two monthly variables | ||
1 | Unemployment rate and PMI | Bayesian AR(6) |
2 | Unemployment rate and ESI | Bayesian AR(6) |
3 | Unemployment rate and PMI | Bayesian VAR(6) with 4 variables |
4 | Unemployment rate and ESI | Bayesian VAR(6) with 4 variables |
5 | Unemployment rate and PMI | ARMA |
6 | Unemployment rate and PMI | ARMA |
formation criterion. In the Bayesian VARs and AR models we always include 6 lags. It is worth noting that in the case of BVARs, the information from more timely predictors (the sentiment indicators) is exploited to forecast the less timely ones (the unemployment rate), see Appendix B. Table 1 provides an overview of the specifications, while Appendix B provides more detail on the auxiliary models. Similarly, to forecast quarterly GDP growth we use Bayesian AR and ARMA models as well.
The advantage of bridge equations is their simple setup, which in some cases have proven more robust to outliers and structural changes. The disadvantage is that they rely on a small number of higher frequency predictors and the choice of the predictors as well as the specification of the predictor equations can be seen as arbitrary. Nevertheless, bridge equations have a long tradition in policy institutions to obtain early estimates of GDP and its components and have been widely used also within the Eurosystem (see e.g. Parigi and Schlitzer, 1995, Ru¨nstler and S´edillot, 2003, Baffigi et al., 2004, Hahn and Skudelny, 2008, Ban´bura and Saiz, 2020).
2.2 Dynamic factor models
As opposed to bridge equations, dynamic factor models (DFMs) can incorporate a large information set containing mixed frequency data within a single framework. The DFM approach is based on the assumption that each observable variable in a large information set can be decomposed into a common and an idiosyncratic component, where the former is assumed to be driven by only a few latent factors. Let yt = [y1,t,...,yn,t]0 denote the vector of observed high frequency (monthly) variables, transformed so as to yield stationary series and standardised to mean 0 and variance 1. We work with the following DFM representation:
![]() (2)
(2)
, (3) ![]() , (4)
, (4)
where ft = [f1,t,...,fr,t]0 collects the common factors and the n×r matrix ? contains the factor loadings. The term ?t = ?ft is known as the common component. The factors are assumed to follow a stationary vector autoregressive process (VAR) of order p, with r × r matrices of coefficients, A1,...,Ap. The idiosyncratic component, ![]() , is assumed to follow a
, is assumed to follow a
variable-by-variable AR(1) process and the innovations, ut and wi,t are uncorrelated at all leads and lags.
In order to deal with the mixed frequency of the data it is assumed that the quarterly variables are monthly but with missing observations, see Appendix B for the details.
In addition to the basic specification as described above we also consider a version with
local” factors, explaining certain blocks of variables (as in Ban´bura et al., 2011, Bok et al., 2018). The advantage in implementing this methodology is that we are able to better account for the contemporaneous correlations within certain pre-defined groups of data. We define the following four types of factors and blocks of data: the Global factor, which is loaded by all the variables, and the local Soft, Real and Labour factors loaded by the variables from the corresponding category (see Table A1 in Appendix A). The block-specific factors are assumed to be mutually independent. Appendix B provides further details.
The models are cast in a state space representation (see Appendix B) and estimated by maximum likelihood using the Expectation Maximisation algorithm as described in Ban´bura and Modugno (2014) and Ban´bura et al. (2011). Forecasts are obtained using the Kalman filter output and missing values are filled in with the help of a Kalman smoother. To account for the uncertainty related to the number of factors and the number of lags in the factor VAR we estimate the models over a range of values for those, see Table 2 for the details.
Table 2: Overview of the DFM model specifications
![]()
Idiosyncratic
Estimation No of factors and lags in factor VAR
component
1 ML without blocks | 1 to 4 factors; 1 to 2 lags | AR(1) |
2 ML with blocks | 1 to 2 factors per block (1111, 2111, 2222); 1 to 2 lags | AR(1) |
3 2-step interpolated quarterly variables | 1 to 4 factors; 1 to 2 lags | i.i.d. |
We also estimate a monthly dynamic factor model in which the quarterly variables are first interpolated to monthly frequency (outside of the model). The model is given by equations (2) and (3) but idiosyncratic components are assumed to be i.i.d. The estimation of the parameters is conducted using the two-step procedure of Doz et al. (2011). Given the estimated parameters, forecasts are generated using the Kalman filter and missing values are filled in with the help of the Kalman smoother. The advantage of this approach compared to the mixed-frequency one is its computational efficiency, since it allows for the inclusion of a large number of quarterly variables without explicitly modelling their latent high-frequency dynamics. In the current exercise we use eight such DFM specifications with the number of latent common factors ranging from one to four and the number of lags in the underlying VAR set to one or two.
3 Data
In order to best capture the various factors that may have a predictive power for quarterly employment growth, we chose a wide range of hard and soft data for the euro area. Precisely, our dataset consists of 37 euro area macroeconomic indicators, 33 of which are collected at monthly and 4 at quarterly frequency. Table A1 in Appendix A provides the details.
For those indicators we construct real-time vintages starting from January 2010, based on the information stored in the ECB’s Statistical Data Warehouse (SDW). For a given date stamp
(vintage) and indicator identifier, a time series available at that date can be recovered from the SDW.[8]Thus, the real-time data vintages reflect both the time-pattern of data publications and data revisions (as opposed to pseudo real-time vintages that reflect only the former). We also account for the enlargement of the euro area from 16 to 19 countries over this period.[9]When a variable is not available for some initial vintages, we create pseudo real-time series based on the earliest available vintage and taking into account the publication lags. We also employ a procedure for cleaning the data from outliers, level shifts and different starting dates of the different vintages of a given indicator. In the latter case, for each series we use the longest available data series in our database in order to backdate its vintages with shorter history. All data are seasonally adjusted and the sample starts in 1995 for most of the series.
The data cover the following categories:
•Quarterly labour market and activity indicators from national accounts: total employment and total hours worked, compensation of employees, GDP;
•Monthly hard indicators related to activity and labour markets: unemployment rates for different groups, industrial production and orders for different sectors;
•Monthly soft indicators related to activity and labour markets from the European Commission consumer and business confidence surveys and Purchasing Managers’ Indexes (PMI);
•Monthly nominal indicators: negotiated wage growth (internal calculations) and HICP
inflation.
4 Forecast evaluation
To provide a fair comparison with the quarterly Eurosystem/ECB staff macroeconomic projections, we aim to replicate a real-time environment as closely as possible, based on the real-time data vintages described in the previous section. Since the availability of real-time vintages is more limited before 2013, we focus on the post-2012 period in the evaluation exercise. Appendix C includes the full sample results. We also show the results for the period affected by the COVID-19 pandemic (starting in 2020Q1) separately, in Sub-section 4.1.
The forecasts based on the model suite and the respective data vintages are generated twice for each month in our evaluation period: on the 10th - when main monthly labour indicators become available; and on the 25th - around which date the Eurosystem/ECB staff macroeconomic projections are typically finalised (in the second month of each quarter). For each data vintage we produce the forecast for employment for the upcoming two quarters to be released. Consequently, for each quarter in the evaluation sample, 12 forecast horizons are considered. The first forecast is obtained on the 25th of the second month of the quarter preceding the reference quarter. Subsequent forecasts are produced in semi-monthly intervals, up to the 10th of the second month of the quarter following the reference quarter (shortly before the publication of the flash estimate at T +45 ).[10]For example, the first forecast for employment growth in the first quarter of 2022 was produced on 25th November 2021 and the last one on 10th May 2022, while flash estimate for that quarter was released on 17th May 2022.
As typical in the literature, we focus on two metrics in the forecast evaluation exercise: the bias (mean forecast error) and the root mean squared forecast error (RMSFE). The forecasts are evaluated against the official first (flash) estimates and against the final (latest available) release of quarter-on-quarter employment growth (downloaded on 25th January 2023).
The forecasting performance of the model suite is compared with that of the Eurosystem/ECB staff macroeconomic projections. For the purpose of the evaluation, we assume that the latter have a cut-off date on the 25th of the second month of each quarter and they remain unchanged in between.
 We look at the accuracy of individual models and also of different levels of aggregation of the model results (forecast averaging). For the latter we take simple averages of forecasts from different groups of models as detailed in Table 3. For the bridge equations we first average the forecasts based on specifications including lagged employment growth, with one or two monthly variables, resulting in BEQ E
We look at the accuracy of individual models and also of different levels of aggregation of the model results (forecast averaging). For the latter we take simple averages of forecasts from different groups of models as detailed in Table 3. For the bridge equations we first average the forecasts based on specifications including lagged employment growth, with one or two monthly variables, resulting in BEQ E  2R and BEQ E 3R combinations, respectively. Second, we average those obtaining BEQ E. We follow similar steps for the specifications with lagged GDP growth, obtaining BEQ Y 2R, BEQ Y 3R and BEQ Y. In the third step we take the average of BEQ E and BEQ Y obtaining the overall forecast from the bridge equation class (BEQ). We follow a similar approach for the DFM class: take the average of the specifications without GDP obtaining DFM E BASE and DFM E BLOCK for specifications without and with block specific factors, respectively, and DFM E for all DFM models without GDP growth. We do the same steps for the specifications with GDP growth to get DFM Y BASE and DFM Y BLOCK, and their average provides DFM Y. We take a simple average of DFM E, DFM Y and of the interpolated DFM (DFM INTERP) forecast averages to get the average for the DFM class (DFM). Finally, we average between the two classes (resulting in All combination). In the main text we show the accuracy measures for the overall average and for the averages over the two main classes.
2R and BEQ E 3R combinations, respectively. Second, we average those obtaining BEQ E. We follow similar steps for the specifications with lagged GDP growth, obtaining BEQ Y 2R, BEQ Y 3R and BEQ Y. In the third step we take the average of BEQ E and BEQ Y obtaining the overall forecast from the bridge equation class (BEQ). We follow a similar approach for the DFM class: take the average of the specifications without GDP obtaining DFM E BASE and DFM E BLOCK for specifications without and with block specific factors, respectively, and DFM E for all DFM models without GDP growth. We do the same steps for the specifications with GDP growth to get DFM Y BASE and DFM Y BLOCK, and their average provides DFM Y. We take a simple average of DFM E, DFM Y and of the interpolated DFM (DFM INTERP) forecast averages to get the average for the DFM class (DFM). Finally, we average between the two classes (resulting in All combination). In the main text we show the accuracy measures for the overall average and for the averages over the two main classes.
Appendix D provides more details for the models within the two classes.
Table 3: Forecast averaging
Averages Calculation (number of specifications included) |

DFM class (DFM) | DFM Y BASE | average of all specifications of the base DFM, estimated with GDP (8) |
DFM Y DFM Y BLOCK | average of all specifications of the DFM with blocks, estimated with GDP (6) | |
DFM INTERP | average of all specifications of the interpolated DFM (8) |
Figure 1 shows the outcome of the target variable in the first (flash) release and in the latest release (taken from the vintage 25th January 2023) and the model nowcasts over 2013-2019. The nowcasts from All models are relatively close to the outcome. Figures 2 and 3 show the root mean squared forecast error (RMSFE) and the bias (mean error), respectively, for the model nowcasts compared to the projections and to a random walk forecast. We show the above measures both compared to the first (flash) estimate and to the latest vintage of employment growth for the 12 forecast horizons considered. The abbreviations used for the forecast horizons reflect whether they are one-quarter-ahead forecasts (F), current quarter nowcasts (N) or previous quarter backcasts (B); the month of the quarter (M1, M2 or M3) and the date of the month (10 or 25). For example, N M2 25 is the nowcast prepared within the reference quarter, in the second month, using data that are available on 25th - for the first quarter of 2022, this would be based on the 25th February 2022 data vintage. This is the closest to the cut-off date of the projections, thus, from this forecast horizon we switch from the forecast of the previous round of the projections to the nowcast in the current one.
The model suite fares well compared to a random walk in the period 2013-2019, but also in comparison to the Eurosystem/ECB staff macroeconomic projections. The accuracy of the model suite (as measured by the root mean squared forecast error) with respect to the projections is similar when evaluated against the first employment release - which is based on a limited information set - and markedly higher when compared to the latest release. At the same time, the model forecasts are less biased relative to both the first and the latest releases. The precision of the model forecasts gradually improves within a quarter as the forecast horizon shortens, although they deteriorate somewhat relative to the first release for mid forecast horizons.
Across the model classes, the performance measures are relatively close to each other. When compared to the first release, the bridge equation class performs somewhat better, both in terms of RMSFE and bias. When compared to the latest release, the forecast combination has the lowest RMSFE and the DFM class has the lowest bias. The comparable performance of the bridge equations and the DFMs suggests that the five indicators exploited by the former model class convey most of the relevant information for employment growth in this period.
Figure 1: Forecasts, 2013Q1-2019Q4
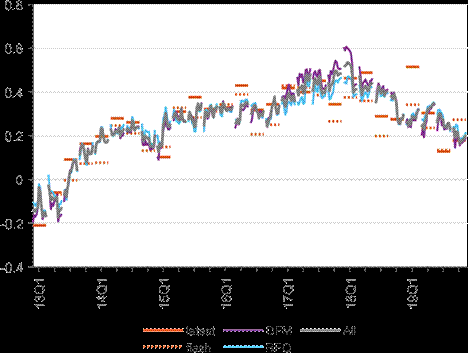
Note: The figure shows the average employment nowcasts from the different model classes with different specifications, as well as the first (dotted red line) and latest (solid red line) release for quarterly employment growth. Vintage of 25th January 2023 was used for the latest release. For each quarter, we show a sequence of 12 forecasts, which are explained in the Note to Figure 2.
Figure 2: Root mean squared forecast error, 2013Q1-2019Q4
a) Relative to the first release b) Relative to the last release

Note: The figure shows the root mean squared forecast errors for the bridge equation (blue) and DFM (purple) classes and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green) and random walk forecast (yellow dotted). The x-axis shows the different forecast horizons, where F, N and B stand for forecast (prepared in the quarter preceding the reference quarter), nowcast (prepared in the reference quarter) and backcast (prepared in the quarter following the reference quarter), respectively. M1, M2 or M3 refer to the month within the quarter and 10 and 25 to the day of the month on which the forecast was obtained.
Figure 3: Bias, 2013Q1-2019Q4
a) Relative to the first release b) Relative to the last release
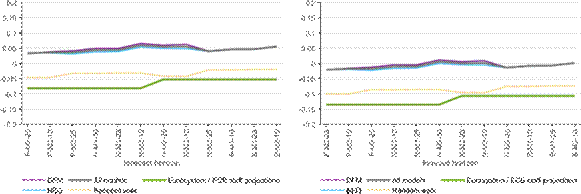
Note: The figure shows the minus average forecast error - the bias - for the bridge equation (blue) and DFM (purple) classes and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green) and random walk forecast (yellow dotted). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
4.1 Forecasting performance during the pandemic period
As a result of the COVID-19 pandemic and the ensuing lockdowns many activity and labour market variables showed unprecedented levels of volatility. This has had an effect on the stability of the (estimated) relationships between the variables, on the size of the residuals in models and consequently on the models’ forecasting performance. Several papers discuss the issues and possible remedies for nowcasting and other time series models (see e.g. Lenza and Primiceri,
2022, Antolin-Diaz et al., 2021, Carriero et al., 2022, Ng, 2021, Schorfheide and Song, 2023, Bobeica and Hartwig, 2023).
In addition, the large-scale use of the job retention schemes in the euro area, on one hand, led to a much more muted response of (un)employment to pandemic developments but on the other hand also distorted the relationship between employment and economic activity indicators. While we used the model suite without implementing any corrections for the high volatility periods of the COVID-19 pandemic, we asses the performance of the model suite separately from the more regular part of our sample.
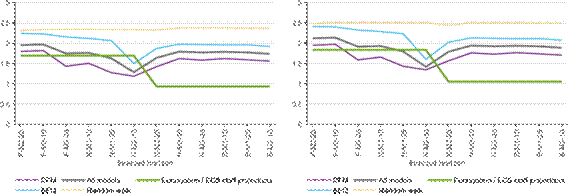
Figure 4 shows the model forecasts over 2020Q1-2022Q3. Following the pandemic shock, the models could not predict well employment developments. The RMSFEs and the bias worsened in 2020, both for the model suite and the projections (Figures 5 and 6, top panels), but in the case of the latter the use of a non-mechanical” approach, and in particular accounting for the effects of the job retention schemes, led to somewhat more accurate nowcasts. While none of the models could provide meaningful nowcasts for the most heavily affected quarters from 2020Q2 to 2020Q4, the performance of the bridge equations that include lagged GDP growth deteriorated most strongly (for reasons explained above). Between the two model classes, the DFM class seems to have performed relatively better during the pandemic period than the bridge equation
class.
The performance of the model suite improved considerably since the start of 2021. Although the RMSFEs remain higher than before the pandemic, this is due primarily to observations in early 2021, when the job retention schemes and pandemic-related restrictions still had an impact. As these started to fade out, the forecasts got closer to the outcome, in particular since 2021Q4. Also, the disagreement of the forecasts decreased and all models performed in a relatively accurate way in the seven quarters that could be evaluated after 2020 (Figures 5 and
6, bottom panels).
Figure 4: Forecasts, 2020Q1-2022Q3
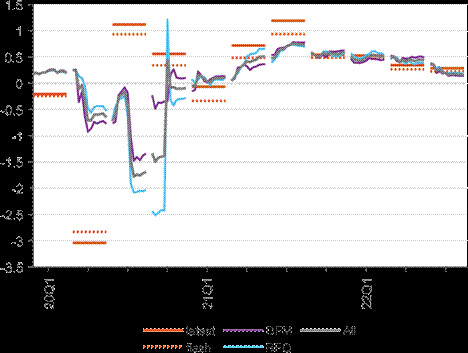
Note: The figure shows the average employment nowcasts from the different model classes with different specifications, as well as the first (dotted red line) and latest (solid red line) release for quarterly employment growth. Vintage of 25 January 2023 was used for the latest release. For each quarter, we show a sequence of 12 forecasts, which are explained in the Note to Figure 2.
Figure 5: Root mean squared forecast error, 2020Q1-2022Q3
2020Q1-2020Q4
a) Relative to the first release b) Relative to the last release
2021Q1-2022Q3
a) Relative to the first release b) Relative to the last release
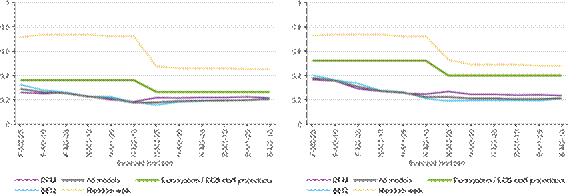
Note: The figure shows the root mean squared forecast errors for the bridge equation (blue) and DFM (purple) classes and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green) and random walk (yellow dotted). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Figure 6: Bias, 2020Q1-2022Q3
2020Q1-2020Q4
a) Relative to the first release b) Relative to the last release

2021Q1-2022Q3
a) Relative to the first release b) Relative to the last release

Note: The figure shows the minus average forecast error - the bias - for the bridge equation (blue) and DFM (purple) classes and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green) and random walk (yellow dotted). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
5 Conclusions
This paper presents a suite of models for nowcasting the quarterly growth rate of total employment, based on a set of monthly and quarterly variables and two model classes: bridge equations and dynamic factor models. The forecasting performance of the model suite is evaluated in real time over 2013-2022 and compared to that of a na¨ive benchmark and of the Eurosystem/ECB staff macroeconomic projections.
The favourable relative performance of the suite, in particular when compared to the judgemental forecasts from the Eurosystem/ECB staff macroeconomic projections, shows the usefulness of model-based nowcasts that exploit monthly information, for a timely assessment of employment developments in the euro area. In particular, the suite could be used to inform the short-term outlook for the labour market in the context of comprehensive forecast exercises at the ECB and elsewhere, similarly to model-based GDP growth nowcasts. It could also serve as the relevant benchmark for future work on this topic.
Avenues for future work could include (i) how the models should be modified in order to make them more robust and accurate also in very volatile periods such as the COVID-19 pandemic (ii) whether novel and higher frequency data, such as e.g. Google trends or data from social platforms or job sites can be used to enhance further the forecast performance.
Bibliography
Aaronson, D., Brave, S. A., Butters, R. A., Fogarty, M., Sacks, D. W., and Seo, B. (2022).
Forecasting unemployment insurance claims in realtime with Google Trends. International Journal of Forecasting, 38(2):567581.
Andreou, E., Ghysels, E., and Kourtellos, A. (2013). Should macroeconomic forecasters use daily financial data and how? Journal of Business & Economic Statistics, 31(2):240251.
Antolin-Diaz, J., Drechsel, T., and Petrella, I. (2021). Advances in nowcasting economic activity: Secular trends, large shocks and new data. CEPR Discussion Papers 15926, C.E.P.R.
Discussion Papers.
Askitas, N. and Zimmermann, K. F. (2009). Google econometrics and unemployment forecasting.
Journal of Econometrics, 55(2):107120.
Baffigi, A., Golinelli, R., and Parigi, G. (2004). Bridge models to forecast the euro area GDP. International Journal of Forecasting, 20:447460.
Ban´bura, M., Giannone, D., and Lenza, M. (2015). Conditional forecasts and scenario analysis with vector autoregressions for large cross-sections. International Journal of Forecasting, 31(3):739756.
Ban´bura, M., Giannone, D., Modugno, M., and Reichlin, L. (2013). Now-casting and the realtime data flow. In Elliott, G. and Timmerman, A., editors, Handbook of Economic Forecasting, pages 195237. North Holland.
Ban´bura, M., Giannone, D., and Reichlin, L. (2010). Large Bayesian VARs. Journal of Applied Econometrics, 25(1):7192.
Ban´bura, M., Giannone, D., and Reichlin, L. (2011). Nowcasting. In Hendry, D. and Clements, M., editors, The Oxford Handbook of Economic Forecasting. Oxford University Press.
Ban´bura, M. and Modugno, M. (2014). Maximum likelihood estimation of factor models on datasets with arbitrary pattern of missing data. Journal of Applied Econometrics, 29(1):133 160.
Ban´bura, M. and Saiz, L. (2020). Short-term forecasting of euro area economic activity at the
ECB. ECB Economic Bulletin, Issue 2/2020, European Central Bank.
Bobeica, E. and Hartwig, B. (2023). The COVID-19 shock and challenges for inflation modelling. International Journal of Forecasting, 39(3):519539.
Bok, B., Caratelli, D., Giannone, D., Sbordone, A. M., and Tambalotti, A. (2018). Macroeconomic nowcasting and forecasting with big data. Annual Review of Economics, 10(1):615643.
Borup, D., Rapach, D. E., and Schu¨tte, E. C. M. (2022). Mixed-frequency machine learning: Nowcasting and backcasting weekly initial claims with daily internet search volume data. International Journal of Forecasting.
Borup, D. and Schu¨tte, E. C. M. (2020). In search of a job: Forecasting employment growth using Google trends. Journal of Business & Economic Statistics, 40(1):186200.
Botelho, V. and Consolo, A. (2021). Monitoring labour market developments during the pandemic. Economic Bulletin 05, European Central Bank.
Brave, S. A., Butters, R. A., and Justiniano, A. (2019). Forecasting economic activity with mixed frequency BVARs. International Journal of Forecasting, 35(4):16921707.
Bundesbank (2018). Models for short-term economic forecasts: an update. Deutsche Bundesbank Monthly Report.
Carriero, A., Clark, T. E., Marcellino, M., and Mertens, E. (2022). Addressing COVID-19 Outliers in BVARs with Stochastic Volatility. The Review of Economics and Statistics, pages 138.
Cimadomo, J., Giannone, D., Lenza, M., Monti, F., and Sokol, A. (2022). Nowcasting with large Bayesian vector autoregressions. Journal of Econometrics, 231(2):500519.
Clements, M. P. and Galva~o, A. B. (2009). Forecasting US output growth using leading indicators: an appraisal using MIDAS models. Journal of Applied Econometrics, 24(7):11871206.
Consolo, A., Foroni, C., and Mart´inez Hern´andez, C. (2023). A mixed frequency bvar for the euro area labour market. Oxford Bulletin of Economics and Statistics.
Doz, C., Giannone, D., and Reichlin, L. (2011). A two-step estimator for large approximate dynamic factor models based on Kalman filtering. Journal of Econometrics, 2011(1):188205.
Evans, M. D. D. (2005). Where are we now? real-time estimates of the macroeconomy. International Journal of Central Banking, 1(2).
Faust, J. and Wright, J. H. (2009). Comparing Greenbook and reduced form forecasts using a large realtime dataset. Journal of Business & Economic Statistics, 27(4):468479.
Faust, J. and Wright, J. H. (2013). Forecasting inflation. In Elliott, G. and Timmermann, A., editors, Handbook of Economic Forecasting, volume 2, pages 256. Elsevier.
Fondeur, Y. and Karam´e, F. (2009). Can Google data help predict French youth unemployment? Economic Modelling, 30(C):117125.
Giannone, D., Reichlin, L., and Small, D. (2008). Nowcasting: The real-time informational content of macroeconomic data. Journal of Monetary Economics, 55(4):665676.
Hahn, E. and Skudelny, F. (2008). Early estimates of euro area real GDP growth a bottom-up approach from the production side. ECB Working Paper Series 975, European Central Bank.
Hirschbu¨hl, D., Onorante, L., and Saiz, L. (2021). Using machine learning and big data to analyse the business cycle. ECB Economic Bulletin, Issue 5/2021, European Central Bank.
Karagedikli, O. and Ozbilgin, M. (2019). Mixed in New Zealand: Nowcasting labour markets¨ with MIDAS. Analytical Note Series 04, Reserve Bank of New Zealand.
Knotek, E. S. and Zaman, S. (2017). Nowcasting U.S. headline and core inflation. Journal of Money, Credit and Banking, 49(5):931968.
Koop, G. and Onorante, L. (2019). Macroeconomic nowcasting using Google probabilities. In
Jeliazkov, I. and Tobias, J. L., editors, Topics in Identification, Limited Dependent Variables, Partial Observability, Experimentation, and Flexible Modeling: Part A. Emerald Publishing Ltd.
Larson, W. D. and Sinclair, T. M. (2022). Nowcasting unemployment insurance claims in the time of COVID-19. International Journal of Forecasting, 38(2):635647.
Lenza, M. and Primiceri, G. E. (2022). How to estimate a vector autoregression after March
2020. Journal of Applied Econometrics, 37(4):688699.
Marcellino, M. and Schumacher, C. (2010). Factor MIDAS for nowcasting and forecasting with ragged-edge data: A model comparison for German GDP. Oxford Bulletin of Economics and
Statistics, 72(4):518550.
Mariano, R. S. and Murasawa, Y. (2003). A new coincident index of business cycles based on monthly and quarterly series. Journal of Applied Econometrics, 18(4):427443.
Matheson, T. (2011). New indicators for tracking growth in real time. IMF Working Papers 11/43, International Monetary Fund.
McCracken, M. W. and Ng, S. (2016). FRED-MD: A monthly database for macroeconomic
research. Journal of Business & Economic Statistics, 34(4):574589.
Mogliani, M., Darn´e, O., and Pluyaud, B. (2017). The new MIBA model: Real-time nowcasting of French GDP using the Banque de France’s monthly business survey. Economic Modelling, 64:2639.
Naccarato, A., Falorsi, S., Loriga, S., and Pierini, A. (2018). Combining official and Google Trends data to forecast the Italian youth unemployment rate. Technological Forecasting and Social Change, 130:114122.
Ng, S. (2021). Modeling macroeconomic variations after Covid-19. NBER Working Papers 29060, National Bureau of Economic Research, Inc.
Pareja, A. A., Loscos, A. G., de Luis L´opez, M., and Quir´os, G. P. (2018). A short-term forecasting model for the Spanish economy: GDP and its demand components. Occasional Papers 1801, Banco de Espan~a.
Parigi, G. and Schlitzer, G. (1995). Quarterly forecasts of the Italian business cycle by means of monthly indicators. Journal of Forecasting, 14(2):117141.
Rapach, D. E. and Strauss, J. K. (2008). Forecasting US employment growth using forecast combining methods. Journal of Forecasting, 27(1):7593.
Ru¨nstler, G., Barhoumi, K., Benk, S., Cristadoro, R., Reijer, A. D., Jakaitiene, A., Jelonek, P., Rua, A., Ruth, K., and Nieuwenhuyze, C. V. (2009). Short-term forecasting of GDP using large data sets: a pseudo real-time forecast evaluation exercise. Journal of Forecasting,
28:595611.
Ru¨nstler, G. and S´edillot, F. (2003). Short-term estimates of euro area real GDP by means of monthly data. Working Paper 276, European Central Bank.
Schorfheide, F. and Song, D. (2015). Real-time forecasting with a mixed-frequency VAR. Journal of Business & Economic Statistics, 33(3):366380.
Schorfheide, F. and Song, D. (2023). Real-time forecasting with a (standard) mixed-frequency var during a pandemic. International Journal of Central Banking, forthcoming.
Appendix A Data
Table A1: Data used in the nowcasting models and groups for block specific factors

Block 1 Block 2 Block 3 Block 4
Number Series name Frequency Transformation Units
Global Soft Real Labour
1 | National accounts employment | q | 1 | 0 | 0 | 1 | pch | Thousands of persons |
2 | Real | q | 1 | 0 | 1 | 0 | p | Million |
gross domestic product | ch | |||||||
3 | Compensation of employees | q | 1 | 0 | 1 | 0 | pch | |
4 | National | q | 1 | 0 | 1 | 0 | p | Quarterly |
ch | hours worked | |||||||
5 | ESI Construction, labour as a factor limiting production | m | 1 | 1 | 0 | 0 | lin | Balance |
6 | ESI | m | 1 | 1 | 0 | 0 | lin | Balance |
Constructions employment expectations (3-months ahead) | ||||||||
7 | m | 1 | 1 | 0 | 0 | lin | Balance | |
8 | ESI | m | 1 | 1 | 0 | 0 | lin | Balance |
Industry employment expectations (3-months ahead) | ||||||||
9 | ESI Retail trade employment expectations (3-months ahead) | m | 1 | 1 | 0 | 0 | lin | Balance |
10 | ESI | m | 1 | 1 | 0 | 0 | lin | Balance |
Service employment expectations (3-months ahead) | ||||||||
11 | ESI Consumers’ unemployment expectations (12-months ahead) | m | 1 | 1 | 0 | 0 | lin | Balance |
12 | Construction | m | 1 | 0 | 1 | 0 | p | |
production | ch | |||||||
13 | m | 1 | 0 | 1 | 0 | pch | ||
14 | Industrial | m | 1 | 0 | 1 | 0 | p | |
new orders, capital goods | ch | |||||||
15 | Industrial new orders, durable consumer goods | m | 1 | 0 | 1 | 0 | pch | |
16 | Industrial | m | 1 | 0 | 1 | 0 | p | |
ch | ||||||||
17 | Industrial new orders, intermediate goods | m | 1 | 0 | 1 | 0 | pch | |
18 | Industrial | m | 1 | 0 | 1 | 0 | p | |
new orders, non-durable consumer goods | ch | |||||||
19 | PMI Composite - Employment | m | 1 | 1 | 0 | 0 | lin | |
20 | m | 1 | 1 | 0 | 0 | lin | ||
Construction - Employment | ||||||||
21 | PMI Manufacturing - Employment | m | 1 | 1 | 0 | 0 | lin | |
22 | m | 1 | 1 | 0 | 0 | lin | ||
Services - Employment | ||||||||
23 | m | 1 | 1 | 0 | 0 | lin | ||
24 | m | 1 | 1 | 0 | 0 | lin | ||
Composite - New Orders | ||||||||
25 | PMI Manufacturing - New Orders | m | 1 | 1 | 0 | 0 | lin | |
26 | m | 1 | 1 | 0 | 0 | lin | ||
Services - New Business | ||||||||
27 | PMI Composite - Productivity | m | 1 | 1 | 0 | 0 | lin | |
28 | m | 1 | 1 | 0 | 0 | lin | ||
Composite - Output | ||||||||
29 | Unemployment rate | m | 1 | 0 | 0 | 1 | chg | % of labour force |
30 | Unemplo | m | 1 | 0 | 0 | 1 | c | % |
yment rate (over 25) | hg | of labour force | ||||||
31 | Unemployment levels (over 25) | m | 1 | 0 | 0 | 1 | pch | Thousands of persons |
32 | Unemplo | m | 1 | 0 | 0 | 1 | p | Thousands |
yment levels (total) | ch | of persons | ||||||
33 | Unemployment rate (under 25) | m | 1 | 0 | 0 | 1 | chg | % of labour force |
34 | Unemployment levels (under 25) | m | 1 | 0 | 0 | 1 | pch | Thousands of persons |
35 | Negotiated wages, yoy | m | 1 | 0 | 0 | 1 | lin | Annual growth rate |
36 | HICP, all-items excluding energy and food | m | 1 | 0 | 0 | 1 | pch | |
37 | m | 1 | 1 | 0 | 0 | chg | Balances |
Note: Frequency: q - quarterly, m - monthly; Transformation: lin - no transformation, pch - percentage change compared to the previous period, chg - first difference.
The observation period of most of the time series start in 1995. Changes in the data keys (for example, due to the changing composition of the euro area) were traced back. Errors in the data and missing data were corrected, including missing observations in some vintages and level shifts. When a variable was not available for some initial vintages, we created pseudo real-time series based on the earliest available vintage and taking into account the publication lags. A detailed description of the data follows below:
•Quarterly real GDP, total employment, total hours worked and compensation of employees are taken from ESA 1995 and ESA 2010 of National Accounts estimated and released by Eurostat for releases ranging from January 2010 to December 2014 and from January 2015, respectively. The base year of volume indicators is 2005, and 2015 as of the beginning of
October 2019. Starting with the 29th of April 2016, the preliminary (first) flash estimate
of the euro area quarterly GDP is published with a delay of 30 days after the end of the quarter of reference. With a delay of 45 days a second flash release of the GDP becomes available together with the flash estimate of employment in total economy. The latter one was first released on the 14th of November 2018. Second official releases of the GDP and employment, as well as the main GDP expenditure components, the different compensation measures, the unit labour costs, and other income data are published with 66 days of delay after the end of the quarter of reference. For the preliminary flash GDP and the flash employment estimate, a coverage of at least 70% of the euro area member states must be ensured for the construction of the euro area aggregates, following a specific weighting aggregation scheme.
•Unemployment rate, number of unemployed, also by age are taken from Eurostat and are based on labour force survey (LFS) and supplementary national sources. The euro area data are normally published by Eurostat around 28-32 days after the reference month. These unemployment rates and numbers are based on definitions recommended by the International Labour Organisation (ILO).
•The opinion surveys include qualitative and quantitative queries addressed both to private households and to business executives. We use two main groups of survey indicators. First, the ECFIN division of the European Commission collects business and consumer surveys (ESI indicators) in the first two weeks of each month, which are published monthly on the second-last working day of the month of reference. The monthly composite confidence indicators are assessed on the basis of individual indicators and are meant to provide an overall perception about the economic conditions in the specific sector. The database includes employment expectations by sectors (industry, services, retail and construction), as well as the overall Economic Sentiment Indicator, which is a weighted average of industrial, services, consumer, construction and retail trade confidence indicators. Second, backward-looking questionnaires are carried out in the Purchasing Manager’s Surveys (PMI) in manufacturing, services, retail trade and construction. These indicators are published on the first, the third and the fourth working days, respectively, as well as every 2nd Monday of the month following the period of reference. For euro area composite PMIs, a flash estimate, based on approximately 85-90% of total PMI survey respondents, is available at around the end of the 3rd week of a month.
•The monthly Short Term Statistics indicators, with the exception of euro area industrial new orders, are provided by Eurostat and are subject to EU Council Regulation. These indicators include statistics from the industrial sector, construction, retail trade, and services. The weighted euro area aggregates cover a minimum of 60% of the euro area country composition, while the most recent observations for the missing country level data are forecast. The provision of euro area monthly industrial new orders indicators, and their breakdowns, had been disrupted by Eurostat as of March 2012. From April 2012 the indicators were published by the Statistical Data Warehouse of the European Central Bank based either on the official national statistical surveys when collected by the member states, or on the model-based estimates carried out by the ECB staff. The aggregated monthly indicators provided by the ECB covered the minimum of 50% of the euro area country composition and are published with a delay of 55 days after the end of the month of reference. From October 2021 the series were discontinued and will be removed from the data set for future updates.
•Nominal variables in our database include HICP inflation excluding energy and food and negotiated wages. Inflation indicators are computed as an annually chain-linked Laspeyrestype index with country- and product group weights changing each year. From January 2016 onwards, the index reference year is 2015. Since April 2013 this aggregate is included in the flash monthly estimates. The indicator of negotiated wage rates has been compiled by the ECB since 2001 based on non-harmonised country data. It is designed to capture the outcome of collective bargaining processes and to provide timely indicator of possible wage pressures (without the effect of wage drift, i.e. the difference between negotiated and actual wages). Quarterly data are published about 40-45 days after the reference quarter.
Our database includes internal calculations on negotiated wages at monthly frequency.
Appendix B Details on the modelling framework
The estimation sample starts in January 1995. We chose a recursive estimation which means that the sample length increases each time that more information becomes available.
B.1 Bridge equations
The quarterly bridge equations are estimated by OLS and the monthly predictor variables are forecast either by Bayesian (V)ARs or by ARMA models. In the Bayesian approach we estimate the parameters using Minnesota priors as in Ban´bura et al. (2010) (for stationary variables). We derive point forecasts using posterior medians of the parameters. To deal with ragged edge we cast the BVARs is a state space representation and obtain the forecasts using Kalman filter and smoother (see Ban´bura et al., 2015). In the univariate specifications the overall shrinkage parameter (?) is set to 0.5 and in multivariate ones to 0.2. In case of the ARMA models, the lag lengths were determined using the Bayesian (Schwarz) information criterion for each monthly indicator and GDP growth.
B.2 Dynamic factor models
The models are specified at monthly frequency. In order to include quarterly variables we follow the approach by Mariano and Murasawa (2003) and treat them as monthly with periodically missing observations. More in detail, let —![]() denote the quarterly growth rates of variables observed at quarterly frequency. We assume that they are linked to their (unobserved) monthly growth rates, ytQ, and to the factors in the following manner:
denote the quarterly growth rates of variables observed at quarterly frequency. We assume that they are linked to their (unobserved) monthly growth rates, ytQ, and to the factors in the following manner:
![]() , (5)
, (5)
where ?—Q = [?Q 2?Q 3?Q 2?Q ?Q] is a (restricted) matrix of loadings on factors and their lags, see also e.g. Ban´bura and Modugno (2014). As in the case of monthly variables, we assume that ?Qt follow an (variable-by-variable) AR(1) process. We follow the convention that the quarterly values are assigned” to the third month of each quarter and —ytQ is not observed in the first and second month.
Collecting (2)-(4) and (5) and assuming p = 2 we obtain the following state space representation:
? ? ? yt ? = ? ? ? | 0 2?Q | 0 3?Q | 0 2?Q | 0 ?Q | In 0 | 0 InQ | 0 2InQ | 0 3InQ | 0 2InQ | 0 InQ | ? ? ft ? ? ? ft-1 ? ? ? ? ? ? ft-2 ? ? ? ? ? ? ft-3 ? ? ? ? ? ? ?? ft-4 ?? ? ? ? ? ?t ? ? ?? ?t ? + ? Q ?(6) | |||||||||
y—tQ | ?Q | |||||||||||||||||||
? ? ? ?Qt ?? ? ? ? ? ?Qt-1 ?? ? ? ? ? ?Qt-2 ?? ? ? ? ? ?Qt-3 ?? ? ? ? ?Qt-4 | ?t | |||||||||||||||||||
? ? ft ? ? ? ft-1 ? ? ? ? ? ? ft-2 ? ? ? ? ? ? ft-3 ? ? ? ? ? ? ft-4 ? ? ? | ? A1 ? ? Ir ? | A2 0 Ir 0 0 0 0 0 0 0 0 | 0 0 0 Ir 0 0 0 0 0 0 0 | 0 0 0 0 Ir 0 0 0 0 0 0 | 0 0 0 0 0 0 0 0 0 0 0 | 0 0 0 0 0 ? 0 0 0 0 0 | 0 0 0 0 0 0 ?Q InQ 0 0 0 | 0 0 0 0 0 0 0 0 InQ 0 0 | 0 0 0 0 0 0 0 0 0 InQ 0 | 0 0 0 0 0 0 0 0 0 0 InQ | ?? | ? | ? ? ut ? ? ? 0 ? ? ? ? ? ? 0 ? ? ? ? ? ? 0 ? ? ? ? ? ? 0 ? ? ? | (7) | ||||||
0 ft-1 ?? ? 0 ?? ft-2 ? ?? ? ?? ? 0 ?? ft-3 ? ?? ? ?? ? 0 ?? ft-4 ? ?? ? ?? ? 0 ?? ft-5 ? ?? ? | ||||||||||||||||||||
? ? ? ? ? ? ? ? ? | 0 0 0 0 0 0 0 0 0 | |||||||||||||||||||
? ? ? ? ?t ?? = ?? ? ? ? ? ?? ?Qt ?? ?? ? ? ? ? ?Qt-1 ?? ?? ? ? ? ? ? ?Qt-2 ?? ?? ? ? ? ? ? ?Qt-3 ?? ?? ? ? ? ? ?Qt-4 | ?? ? ? ? 0 ?? ?t-1 ?? + ?? wt ?? , ?? ?? ? ? ? 0 ???? ?Qt-1 ?? ?? wtQ ?? ?? ? ? ? ?? ?Qt-2 ?? ?? 0 ?? 0 ?? ?? ? ? ? 0 ???? ?Qt-3 ?? ?? 0 ?? ?? ? ? ? 0 ???? ?Qt-4 ?? ?? 0 ?? ?? ? ? ? 0 ?Qt-5 0 | |||||||||||||||||||
where ? = diag (?1,...,?n), wt = [w1,t,...,wn,t]0 and similar logic applies to ?Q and wtQ.
The parameters are estimated by maximum likelihood using the Expectation-Maximisation (EM) algorithm following Ban´bura and Modugno (2014). As discussed in that paper, the terms ?tM and ?tQ have fixed and small variance and are included for computational reasons. The EM algorithm iterates between two steps. In the expectation step the expectations of the state variables and the associated uncertainty are obtained from the Kalman filter and smoother. In the maximisation step the parameter estimates are updated using the input from the expectation step. The initial values of the parameters are obtained based on the principal component analysis and OLS estimates. Details can be found in Ban´bura and Modugno (2014). In particular, the algorithm can easily handle arbitrary patterns of missing data, such as those caused by mixed frequency, some data having a short history or the ragged edge due to differences in publication delays.
In the implementation with blocks”, the monthly variables are grouped into Soft, Real
![]() 0
0
and Labour blocks:. Each variable loads then on a global factor and the
corresponding local” factor. Consequently, the terms in the state space representation have the following restrictions:

The restrictions on ?Q are analogous to those for ?. The parameters are estimated by maximum likelihood using the EM algorithm. For the details we refer to Ban´bura et al. (2011).
For the DFM version with interpolated quarterly variables the interpolation of the series is done by a shape-preserving piece-wise cubic method. The two-step procedure involves the following. First, latent static factors are extracted from the balanced part of the dataset (discarding the part with the ragged edge) using principal component analysis. In a second step factor loadings and VAR parameters are estimated using the OLS on the principal components (see Doz et al., 2011, for details). Finally, the estimated coefficients are used to re-estimate the factors and derive the forecasts for the variable of interest based on the entire dataset (including the ragged edge) using the Kalman filter and smoother. The state space representation can be obtained in a straightforward manner from (2) and (3) with ?t being i.i.d.
Appendix C Forecast performance 2010-2019
Figure C1: Root mean squared forecast error, 2010Q3-2019Q4
a) Relative to the first release b) Relative to the last release
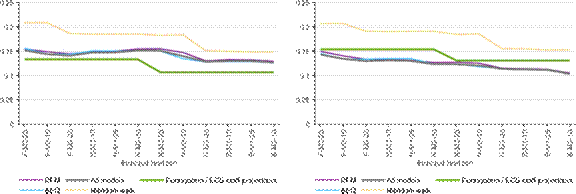
Note: The figure shows the root mean squared forecast errors for the bridge equation (blue) and DFM (purple) classes and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green) and random walk (yellow dotted). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Figure C2: Bias, 2010Q3-2019Q4
a) Relative to the first release b) Relative to the last release
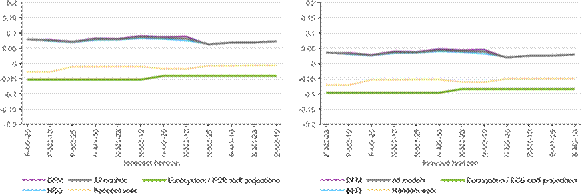
Note: The figure shows the minus average forecast error - the bias - for the bridge equation (blue) and DFM (purple) classes and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green) and random walk (yellow dotted). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Appendix D Forecast performance 2013-2019, details
Figure D1: Root mean squared forecast error, DFM class, 2013Q1-2019Q4
a) Relative to the first release b) Relative to the last release
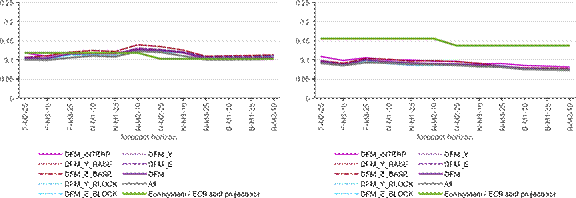
Note: The figure shows the root mean squared forecast errors for the models within the DFM class (blue and purple lines) and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Figure D2: Bias, DFM class, 2013q1-2019Q4
a) Relative to the first release b) Relative to the last release
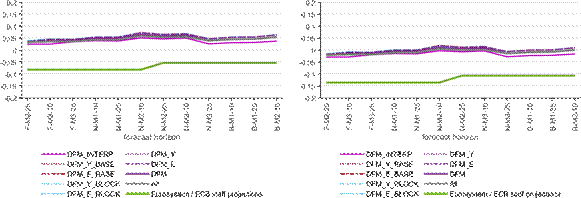
Note: The figure shows the minus average forecast error - the bias - for the models within the DFM class (blue and purple lines) and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Figure D3: Root mean squared forecast error, bridge equation class, 2013Q1-2019Q4
a) Relative to the first release b) Relative to the last release
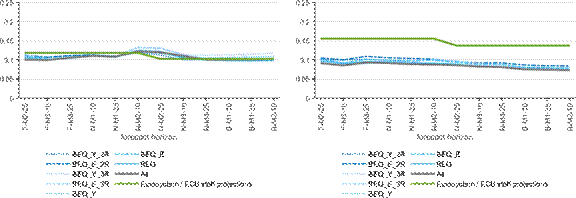
Note: The figure shows the root mean squared forecast errors for the models within the bridge equation class (blue lines) and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Figure D4: Bias, bridge equation class, 2013q1-2019Q4
a) Relative to the first release b) Relative to the last release
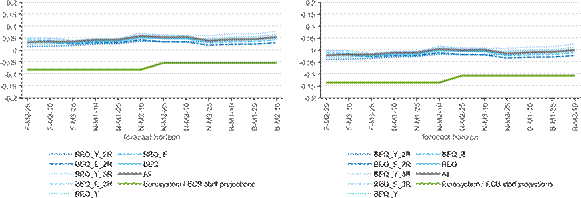
Note: The figure shows the minus average forecast error - the bias - for the models within the bridge equation class (blue lines) and for the overall average (grey), compared to the Eurosystem/ECB staff macroeconomic projections (green). The x-axis shows the different forecast horizons, which are explained in the Note to Figure 2.
Acknowledgements
We thank David Sondermann, Colm Bates and the participants of the ECB’s Brownbag seminar for useful comments. The views expressed are those of the authors and do not necessarily reflect those of the European Central Bank or the Eurosystem.
Marta Bańbura
European Central Bank, Frankfurt am Main, Germany; email: marta.banbura@ecb.europa.eu
Irina Belousova
Joint Research Centre, European Commission, Seville, Spain; email: irina.belousova@ec.europa.eu
Katalin Bodnár
European Central Bank, Frankfurt am Main, Germany; email: katalin.bodnar@ecb.europa.eu
Máté Barnabás Tóth
European Central Bank, Frankfurt am Main, Germany; email: mate.toth@ecb.europa.eu
Postal address 60640 Frankfurt am Main, Germany
Telephone +49 69 1344 0
Website www.ecb.europa.eu
All rights reserved. Any reproduction, publication and reprint in the form of a different publication, whether printed or produced electronically, in whole or in part, is permitted only with the explicit written authorisation of the ECB or the authors.
This paper can be downloaded without charge from www.ecb.europa.eu, from the Social Science Research Network electronic libraryor from RePEc: Research Papers in Economics. Information on all of the papers published in the ECB Working Paper Series can be found on the ECB’s website.
PDF ISBN 978-92-899-6078-6 ISSN 1725-2806 doi:10.2866/634513 QB-AR-23-052-EN-N
[1] Flash estimates for euro area employment are released since November 2018. They are computed on the basis of national estimates by member states altogether covering 91% of EA-19 GDP. Before that, employment data were released with a publication lag of 75 days.
[2] See, for example, Ban´bura and Saiz (2020), Bok et al. (2018), Bundesbank (2018), Matheson (2011), Mogliani et al. (2017), Pareja et al. (2018) or Ru¨nstler et al. (2009).
[4] Other types of models frequently used for nowcasting are the mixed frequency VARs (see e.g. Schorfheide and Song, 2015, Brave et al., 2019, Cimadomo et al., 2022) and MIDAS models (see e.g. Clements and Galv~ao, 2009, Marcellino and Schumacher, 2010, Andreou et al., 2013).
[6]Ban´bura and Saiz (2020) compare the accuracy of model-based nowcasts and of Eurosystem/ECB staff macroeconomic projections for euro area GDP growth over the period 2005-2019 and they find a comparable forecast performance, with the projections performing somewhat better since 2013. See also e.g. Faust and Wright (2009), Faust and Wright (2013) or Knotek and Zaman (2017).
[7] In certain situations, for example during the COVID-19 pandemic, employment developments deviate from those in output. For this reason, we compared equations with and without lagged GDP growth and examine their forecast performance separately as well as jointly.
[8] We are thankful to Dimitra Ralli and Colm Bates who developed the procedure to download the real-time vintages from SDW.
Poslední zprávy z rubriky Měny-forex:
Přečtěte si také:

Benzín a nafta 22.04.2024
| Natural 95 40.3 Kč | Nafta 39.26 Kč |
Prezentace
23.04.2024 Podle čeho vybírat plechový zahradní domek?
18.04.2024 Daňové přiznání lidem provětralo peněženky....
Okénko investora

Michal Brothánek, AVANT IS

Olívia Lacenová, Wonderinterest Trading Ltd.
Evropský průmysl zelené energie má problém: Společnosti se stěhují do USA

Mgr. Timur Barotov, BHS
Trhy střízliví a vedou ruku amerického Fedu ke zpřísnění politiky

Petr Lajsek, Purple Trading

Miroslav Novák, AKCENTA
Spotřebitelská inflace v eurozóně odeznívá, pro služby to však úplně neplatí

Jiří Cimpel, Cimpel & Partneři

Ali Daylami, BITmarkets
Bitcoin stanovil nové historické maximum – Je už na nákup pozdě?

Jakub Petruška, Zlaťáky.cz

